
Generating PDF reports using puppeteer
Exporting website content including web.gl maps and canvas charts to pdf can be difficult and frustrating. In this article I will show you the easy parts, but also dig into the hard parts when trying to generate full-fledged pdf reports.
Prelude
We were faced the challenge of exporting dashboard content to readable or printable formats so that our data visualizations can be sent via scheduled email summaries or pdf reports that can be used for presentations.
Preparations
We defined a architecture that an cli interface that accesses a statically built website (raw html, css and js files) or accesses a provided url to an website which gets exported in a specific format.
- For textual formats our react components should return the data that should be visualized in text form
- For the pdf format it should return the data visualization in its chart or map form plus a short summary in text form
- And when opening the specific dashboard on the web it should render the data visualization so it is interactive with tooltips and hover highlighting
The "Easy" Part
The first running prototype after the initialization of the project was set up in a couple of steps and worked like a charm without any problems.
// pdf-generator.ts
import Debug from 'debug';
import express from 'express';
import fs from 'fs';
import path from 'path';
import puppeteer from 'puppeteer-core';
import util from 'util';
const debug = Debug('pdf-generator');
const writeFileAsync = util.promisify(fs.writeFile);
const pdfOptions = {
format: 'a4',
margin: {
top: 0,
bottom: 0,
left: 0,
right: 0,
},
};
const createExpressServer = (port = 13770) =>
new Promise((resolve) => {
const app = express();
const server = app.listen(port, () => {
resolve({ app, server });
});
server.on('error', () => {
resolve(createExpressServer(port + 1));
});
});
interface IArgs {
chromeExecutable: string;
outputPath?: string;
url?: string;
}
interface IPdfGeneratorParams {
args: IArgs;
}
const pdfGenerator = async ({ args }: IPdfGeneratorParams) => {
try {
if (!args.chromeExecutable) {
console.error('A executable path to an chromium instance is needed!');
process.exit();
}
let server;
let url = args.url;
if (!url) {
const expressServer = await createExpressServer();
const { app } = expressServer;
server = expressServer.server;
const { port } = server.address();
debug('Express server initiated on port', port);
const pathToStaticFiles = path.join(__dirname, '..');
debug('Serving static file from', pathToStaticFiles);
app.use('/', express.static(pathToStaticFiles));
url = `http://127.0.0.1:${port}`;
}
debug('Launching chrome browser at', args.chromeExecutable);
const browser = await puppeteer.launch({
executablePath: args.chromeExecutable,
headless: true,
});
const page = await browser.newPage();
debug('waiting for dom');
await page.goto(url, { waitUntil: 'load' });
debug('dom loaded');
await page.emulateMediaType('print');
await page.evaluateHandle('document.fonts.ready');
const pdfContent = await page.pdf(pdfOptions);
await browser.close();
if (server) await server.close();
debug('Closed chrome instance and express server');
const buffer = Buffer.from(pdfContent, 'base64');
if (args.outputPath) {
debug('Writing file at', args.outputPath);
await writeFileAsync(args.outputPath, buffer);
debug('PDF generation has been successfully finished!');
return args.outputPath;
}
debug('Return pdf content to stdout');
return process.stdout.write(buffer);
} catch (err) {
console.error(err);
process.exit(1);
}
};
export default pdfGenerator;
The above code accepts argument variables parsed by yargs for example but can also be executed in a code directly. When a url is provided, the following website is being rendered using a headless chrome and the content written to a pdf. Otherwise this code expects that a statically built website is being provided at the path at .. Using the outputPath argument you can control if the pdf should be written directly to the disk or should be returned to the stdout for further processing.
Challenges
As easy as the above steps were, our ecosystem of react components and data that should be visualized in different ways made the following steps frustrating to that point that you would like to quit. But in the end - you should try to figure out the problems and try to handle them, instead of taking the easy route by just avoiding the problem and quitting - you will get so much experience from it.
Fonts
The data visualization dashboards we are trying to render as pdf come in a different branding based on the costumer - every branding has its own custom fonts. But when generating a pdf page with puppeteer the font needs to be installed on the machine where the pdf is being opened, or included into the pdf.
For that we need to create a raw pdf and embed the fonts needed into the document.
// pdf-generator.ts
// ...new imports
import fontkit from '@pdf-lib/fontkit';
import { PDFDocument } from 'pdf-lib';
import glob from 'fast-glob';
// ...rest code
const pdfContent = await page.pdf(pdfOptions);
await browser.close();
if (server) await server.close();
debug('Closed chrome instance and express server');
// ...new code
const finalPdf = await PDFDocument.create();
finalPdf.registerFontkit(fontkit);
const fontsToInclude = await glob(
path.join(__dirname, 'static', '**', '*.ttf')
);
await Promise.all(
fontsToInclude.map(async (fontToInclude) => {
const fontBytes = await fs.promises.readFile(fontToInclude);
return finalPdf.embedFont(fontBytes);
})
);
const content = await PDFDocument.load(pdfContent);
const contentPages = await finalPdf.copyPages(
content,
content.getPageIndices()
);
for (const contentPage of contentPages) {
finalPdf.addPage(contentPage);
}
const buffer = Buffer.from(finalPdf, 'base64');
// ...rest code
Charts & Maps
The next wall we were facing were our charts and maps. We use charts from nivo for our data visualizations and deck.gl, which is based on mapbox-gl. Both solutions did not render in our pdf documents because they are based on canvas and web.gl - we needed an solution.
So we brainstormed and decided that a rendered image of these visualizations would be the way to go. For this we added .canvas-to-img class to those dom elements, which gets selected by puppeteer. Each of those elements gets replaced by a base64 inline image, where puppeteer takes an screenshot of it when it is finished loading.
// pdf-generator.ts
await page.evaluateHandle('document.fonts.ready');
// ...new code
const canvasToImageElements = await page.$$('.canvas-to-image');
if (canvasToImageElements.length) {
const canvasToImagePromises = canvasToImageElements.map(
async (canvasToImageElement) => {
const base64Screenshot = await canvasToImageElement.screenshot({
encoding: 'base64',
});
await canvasToImageElement.$eval(
'*',
(element, base64) => {
element.style.display = 'none';
element.outerHTML = `<img src="data:image/png;base64, ${base64}" />`;
},
base64Screenshot
);
}
);
await Promise.all(canvasToImagePromises);
}
// ...rest code
const pdfContent = await page.pdf(pdfOptions);
Fetching Data
Since we rely on fetching data from the GraphQL API, we needed a way to reliably wait for all asynchronous data to be retrieved successfully. On top of that our web.gl maps rely on maptiles (for generating pdfs we needed to switch to raster maptiles instead of vector maptiles) - which makes up to 30-50 requests to png tiles based on the zoom level of the map. And we needed to make sure that all maptiles are finished loading before making a screenshot - otherwise we would render shapes on a blank canvas/map which does not make a great map for that sake.
For this we found a great solution in the comments of an issue in puppeteer - https://github.com/puppeteer/puppeteer/issues/3627#issuecomment-884470195. We did change it up a bit, because we soon realized that the request handle was not same throughout the request, and a HashMap of the request id is the more reliable solution:
// createFunctionWaitForIdleNetwork.ts
import Debug from 'debug';
import EventEmitter from 'events';
const debug = Debug('pdf-generator:createFunctionWaitForIdleNetwork');
export function createFunctionWaitForIdleNetwork(page) {
class Emitter extends EventEmitter {}
const pendingRequestIds = new Set();
const emitter = new Emitter();
function pushRequest(request) {
pendingRequestIds.add(request._requestId);
emitter.emit('active');
}
function popRequest(request) {
pendingRequestIds.delete(request._requestId);
if (pendingRequestIds.size === 0) {
emitter.emit('idle');
}
}
function emitFailed(request) {
pendingRequestIds.delete(request._requestId);
emitter.emit('fail');
}
page.on('request', pushRequest);
page.on('requestfinished', popRequest);
page.on('requestfailed', emitFailed);
/**
* Return a promise that will resolve when the network is idle.
*
* @param idleTimeout
* The minimum amount of time that the network must be idle before the promise will resolve.
*
* @param failTimeout
* The maximum amount of time to wait for the network to become idle before rejecting.
*/
async function waitForIdleNetwork(idleTimeout, failTimeout) {
debug('idleTimeout ', idleTimeout);
debug('failTimeout ', failTimeout);
let failTimer;
let idleTimer;
return new Promise((resolve, reject) => {
debug('waiting for idle network...');
function fail() {
reject(
new Error(
`After ${failTimeout}ms, there are still ${pendingRequestIds.size} pending network requests.`
)
);
}
function succeed() {
clearTimeout(failTimer);
resolve();
}
function failed() {
clearTimeout(idleTimer);
reject(
new Error(
`A network request has failed, there are still ${pendingRequestIds.size} pending network requests.`
)
);
}
// Start failure time immediately.
failTimer = setTimeout(fail, failTimeout);
// Handle edge case where neither active nor idle is emitted during the lifetime of this promise.
setTimeout(() => {
if (pendingRequestIds.size === 0) {
debug('after initialization, there are still no network requests');
idleTimer = setTimeout(succeed, idleTimeout);
}
}, process.env.PUPPETEER_WAITFOR_TIMEOUT || 1000);
// Play a game of whack-a-mole with the idle and active events.
emitter.on('idle', () => {
idleTimer = setTimeout(succeed, idleTimeout);
});
emitter.on('active', () => {
clearTimeout(idleTimer);
});
emitter.on('failed', failed);
});
}
return waitForIdleNetwork;
}
// pdf-generator.ts
// ...new imports
import createFunctionWaitForIdleNetwork from './createFunctionWaitForIdleNetwork';
// ...rest code
await page.evaluateHandle('document.fonts.ready');
// ...new code
const waitForIdleNetwork = createFunctionWaitForIdleNetwork(page);
const IDLE_TIMEOUT = parseInt(process.env.PUPPETEER_IDLE_TIMEOUT || 1000, 10);
const FAIL_TIMEOUT = parseInt(
process.env.PUPPETEER_FAIL_TIMEOUT || 30 * 1000,
10
);
await waitForIdleNetwork(IDLE_TIMEOUT, FAIL_TIMEOUT);
//
const mapToImageElements = await page.$$('.map-to-image');
Page Breaks
To control how the data is being visualized, you can add this css syntax to any dom element:
page-break-after: always;
Header & Footer
To display a header and footer on each page - puppeteer provides a headerTemplate and footerTemplate which should be a valid html string that injects custom variables like date, title and pageNumber (see puppeteer api) into it using classes:
const pdfContent = await page.pdf({
...pdfOptions,
footerTemplate: `
<span style="font-size: 10px">
<span class="pageNumber"></span>/<span class="totalPages"></span>
</span>
`,
});
The problem we faced was, that our custom fonts were not inherited in the header and footer... So puppeteer's headerTemplate and footerTemplate was no option for us. Luckily we found the great library puppeteer-report. From the puppeteer-report documentation:
To support headers or footers, Puppeteer Report creates two PDF files. The first one is the HTML content without header and footer. And the second one is header and footer repeated based upon original content PDF pages' number, then it merges them together.
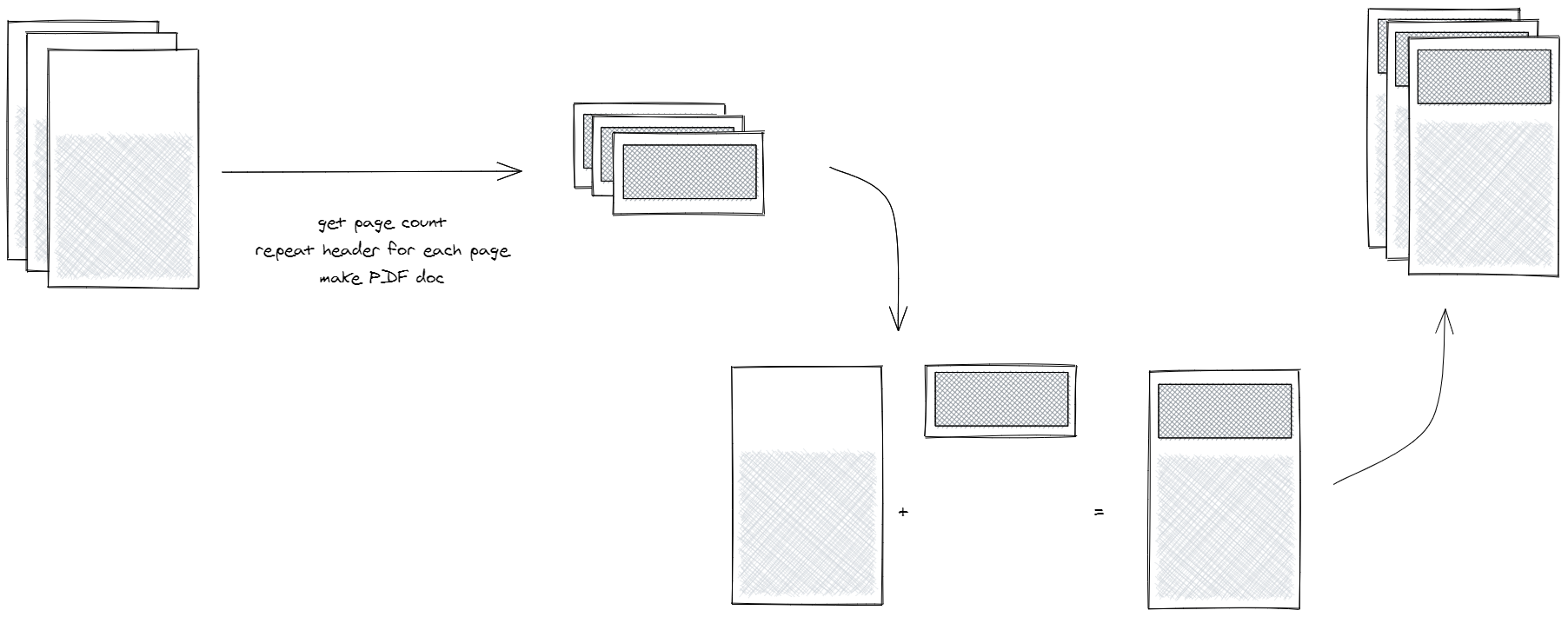
// pdf-generator.ts
// ...new imports
import report from 'puppeteer-report';
// ...rest code
- const pdfContent = await page.pdf(pdfOptions);
+ const pdfContent = await report.pdfPage(page, pdfOptions);
Then we simply need to place a html markup that includes a id="header" or id="footer" to indicate that this dom element needs to be repeated on every page.
<header id="header">
{logo ? <img className="logo" src={logo} alt="Logo" /> : null}
{title ? <div className="title">{title}</div> : null}
</header>
Cover Page
A cover page is another specialty in that it should not render the header or the footer and the pageNumber should be offset by it.
For this we simply added a component that is only displayed when @media print.
// CoverPage.tsx
const StyledCoverPage = styled.div`
display: none;
page-break-after: always;
@media print {
display: block;
}
`;
export const CoverPage = (): React.JSX.Element => (
<StyledCoverPage id="cover">...your cover page</StyledCoverPage>
);
But to avoid the header & footer on this cover page and to offset the pageNumber we need to change our injected header and footer:
// Footer.tsx
import React, { useCallback, useLayoutEffect } from 'react';
export const Footer = (): React.JSX.Element => {
const handleOnChange = useCallback((event) => {
if (event.target.id !== 'footer') return;
const pageNumberElement =
event.target.getElementsByClassName('pageNumber')[0];
if (pageNumberElement.textContent === '1') {
event.target.style.visibility = 'hidden';
}
pageNumberElement.textContent =
parseInt(pageNumberElement.textContent, 10) - 1;
}, []);
useLayoutEffect(() => {
document.addEventListener('change', handleOnChange);
window.isReady = true;
return () => {
document.removeEventListener('change', handleOnChange);
};
}, [handleOnChange]);
return (
<div id="footer">
<span className="pageNumber" />
</div>
);
};
The code simply hides the footer when its content is "1" and subtracts 1 from every other pages. On the header we use a similar code, that just hides the header on the cover page.
Summary
We had a lot of challenge, but in the end it was worth trying to figuring out how to solving them. I created a repository demonstrating the code at https://github.com/ChiefORZ/pdf-generator - it is used under the hood here on this portfolio to download the printable CV.